What is the underlying mechanism for data replication in Cosmos DB?
In a previous post, I covered the five different consistency levels Cosmos offers. We saw that choosing a consistency level requires evaluating a trade off in data consistency, availability and performance. In this post, I explore how Cosmos DB enforces consistency.
From the Microsoft documentation page on Consistency levels in Azure Cosmos DB we have:
For strong and bounded staleness, reads are done against two replicas in a four replica set (minority quorum) to provide consistency guarantees. Session, consistent prefix and eventual do single replica reads. The result is that, for the same number of request units, read throughput for strong and bounded staleness is half of the other consistency levels.
For a given type of write operation, such as insert, replace, upsert, and delete, the write throughput for request units is identical for all consistency levels. For strong consistency, changes need to be committed in every region (global majority) while for all other consistency levels, local majority (three replicas in a four replica set) is being used.
We also get the following table:
| Consistency Level | Quorum Reads | Quorum Writes |
|---|---|---|
| Strong | Local Minority | Global Majority |
| Bounded Staleness | Local Minority | Local Majority |
| Session | Single Replica (using session token) | Local Majority |
| Consistent Prefix | Single Replica | Local Majority |
| Eventual | Single Replica | Local Majority |
What does this all mean? What are quorums, replica sets, global majority, local majority, and local minority. In this post we will figure it out together.
Quorums and consensus
- Quorum
-
The smallest number of people needed to be present at a meeting before it can officially begin and before official decisions can be taken. 1
- A more technical definition of a quorum is as follows:
-
A quorum is the minimum number of votes that a distributed transaction has to obtain in order to be allowed to perform an operation in a distributed system. A quorum-based technique is implemented to enforce consistent operation in a distributed system. 2
So a quorum is a collection of replicas communicating in such a way to ensure data consistency. Cosmos DB groups four replicas (one leader, three followers) within a physical partition to form a replica set. The leader is responsible for propagating writes within the replica set. And within the replica set we can group replicas together to for a quorum

How then are quorums involved in ensuring a write or read is successful?
Quorum Writes and Reads
Under strong consistency, a write is deemed successful if every replica can agree on the most recent write. This comes at the price of decreased performance as every replica must have the latest value written to it for the system to agree on the current state.
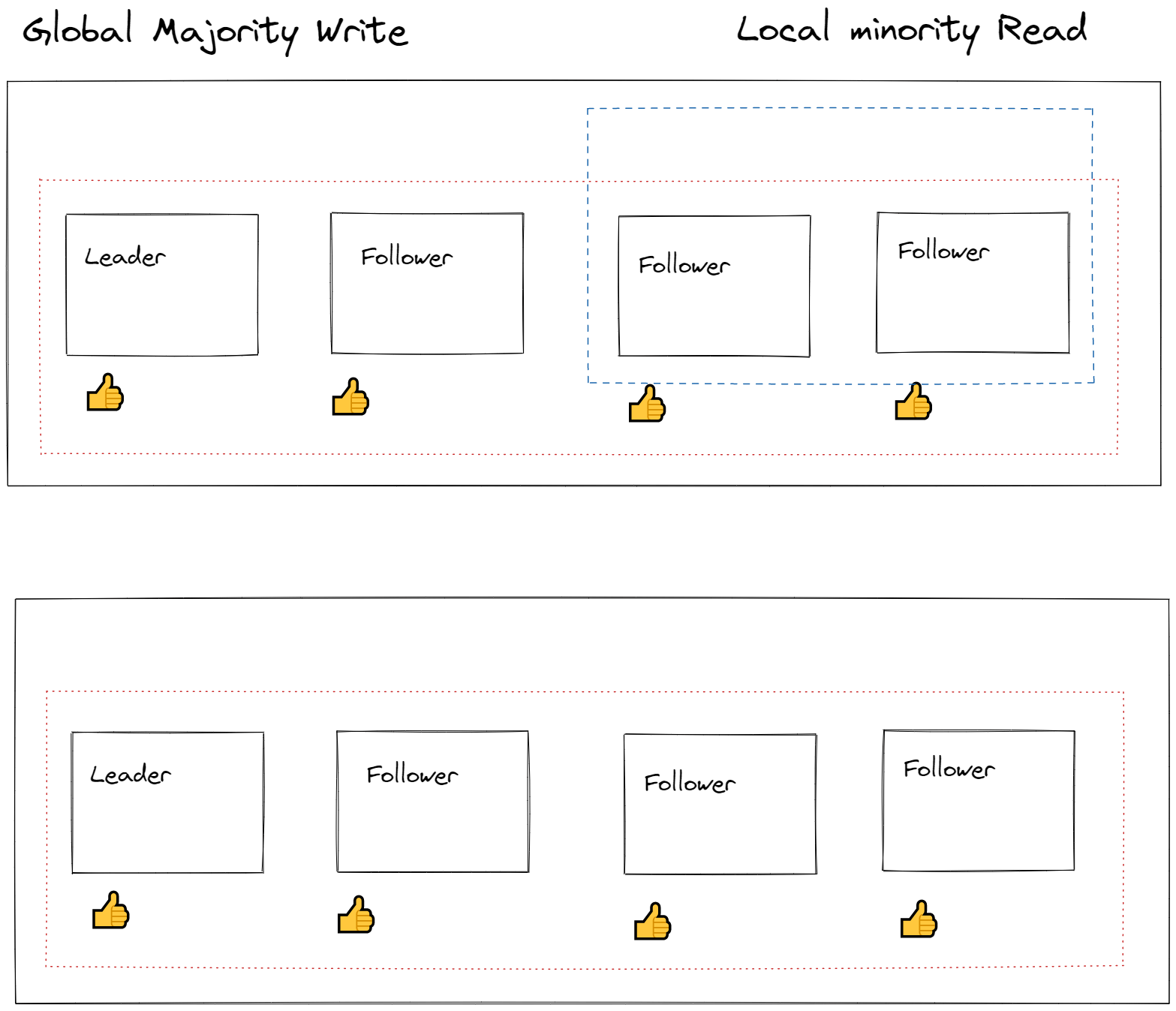
For consistency levels other than strong, a local majority is used. This means when writing to a replica set (four instances of the data), only three of the four replicas have to be up to date at any given time for a write to be acknowledged. This keeps latency lower as if one replica was unavailable the write could still be acknowledged by the database.
For quorum reads, the convention is similar. Strong and bounded staleness, reads are done against a local majority; two replicas in a four replica set, this means two replicas have to agree on seeing the same value for a read to be acknowledged. In the diagram below the bounded staleness partition-set reads from a quorum in which two partitions have the been updated to the latest value.
We can imagine the leader and two followers enclosed in the dotted line as writing a value and then a reader milliseconds later querying the same value from the replica set as the dashed box. As both boxes overlap we are guaranteed to see the latest written value.
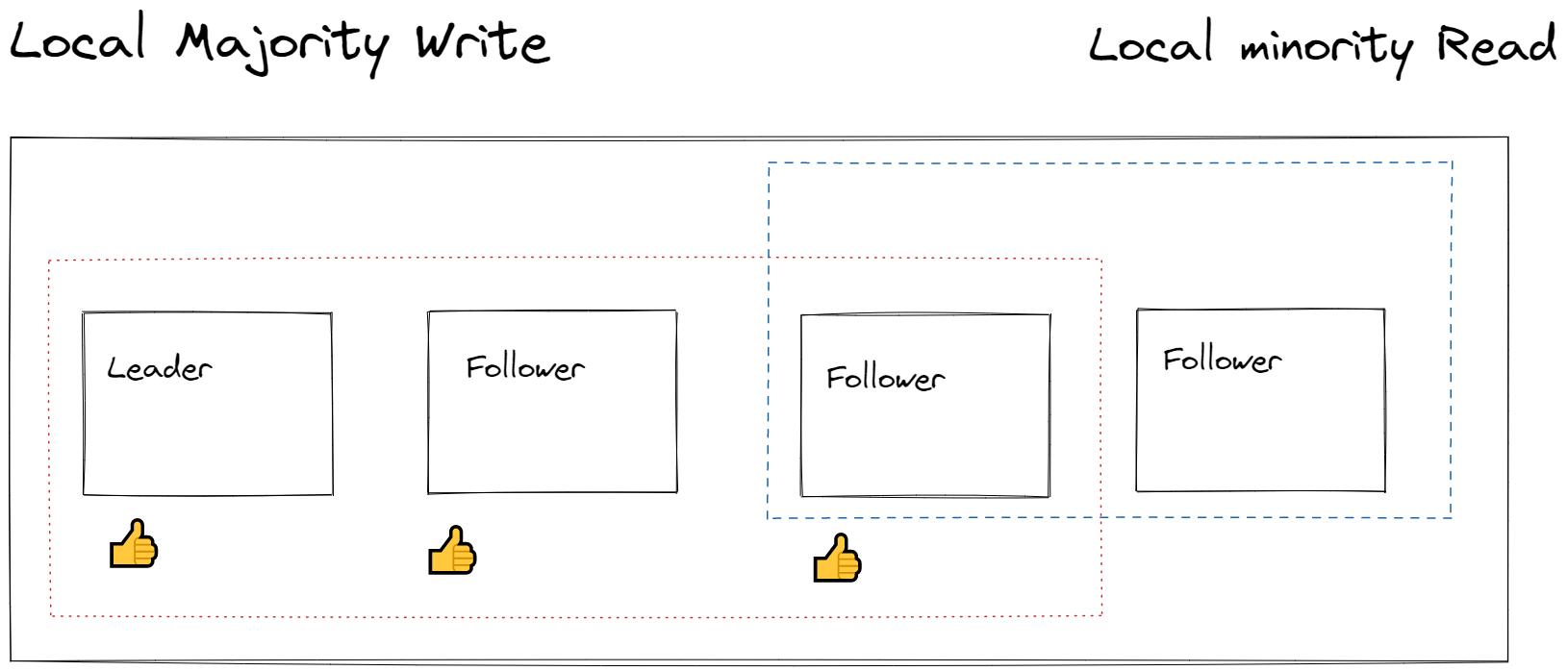
Session, consistent prefix and eventual reads are done through single replicas. As shown in the diagram below, comes at a cost of reading stale data.
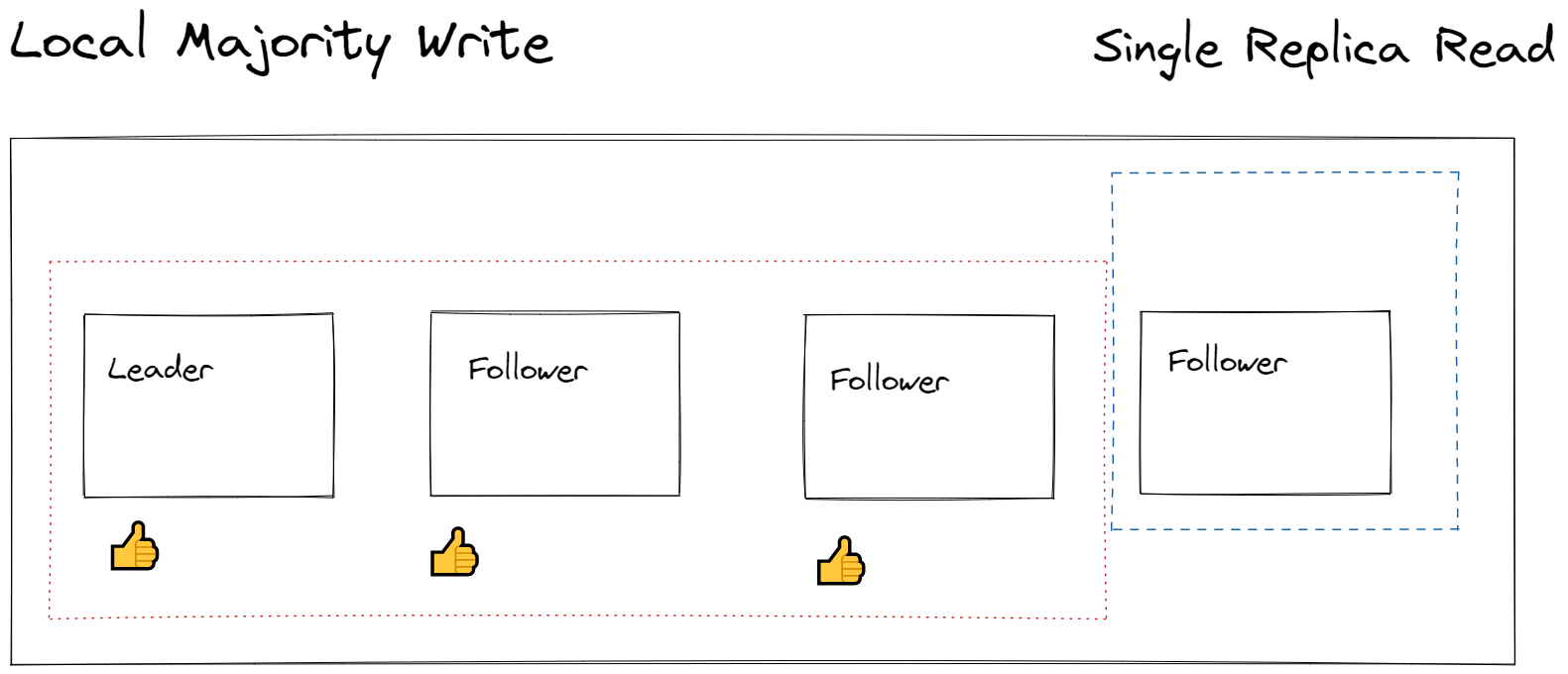
The quorum reads and quorum writes are the same for session, consistent prefix and eventual. This explains why write latencies, availability and read throughput for session and consistent prefix are comparable to eventual consistency.
Quorum consensus
In general, with \(n\) replicas in a replica set, every write must be confirmed by \(w\) nodes to be considered a successful write. We must query at least \(r\) nodes for each read. As long as \(w + r > n\) we expect to get an up-to-date value when reading; at least one of the \(r\) nodes we are reading from must be up-to-date.
Reads and writes obeying \(r\) and \(w\) values are called quorum reads and writes.
At least one node needs to overlap:
- \(w \geq (n - r) + 1\) and \(r \geq (n - w) + 1\)
- thus \(w > n - r\) and \(r > n - w\)
- thus \(w + r > n\)
Probabilistic Bounded Staleness
You may have noticed that under bounded staleness, the quorum consensus set up ensure we always see the latest value. However, bounded staleness can allow stale reads. This occurs when we replicate our data across multiple replica sets. Here we are not guaranteed strong consistency as one quorum may not have received the latest write.
Instead, we can use a metric called probabilistic bounded staleness to determine the probability of getting strongly consistent reads for a combination of write and read regions.
In Conclusion
Quorums are one mechanism which explains why different consistency levels have differing performance characteristics. In this post we defined what quorums are and how Cosmos DB uses them to enforce consistency constraints.